

Last updated: November 03, 2024
Read this guide to learn how to verify that text and numeric columns contain accepted values. Assert that all expected values are used in tested columns.
Bạn đang xem: How to validate accepted values in columns
Accepted values category
Data quality checks for asserting accepted values in columns are defined in the accepted_values category of data quality checks.
What is an accepted value
An accepted value is a well-known value that we expect to be used as one of the values in a column.
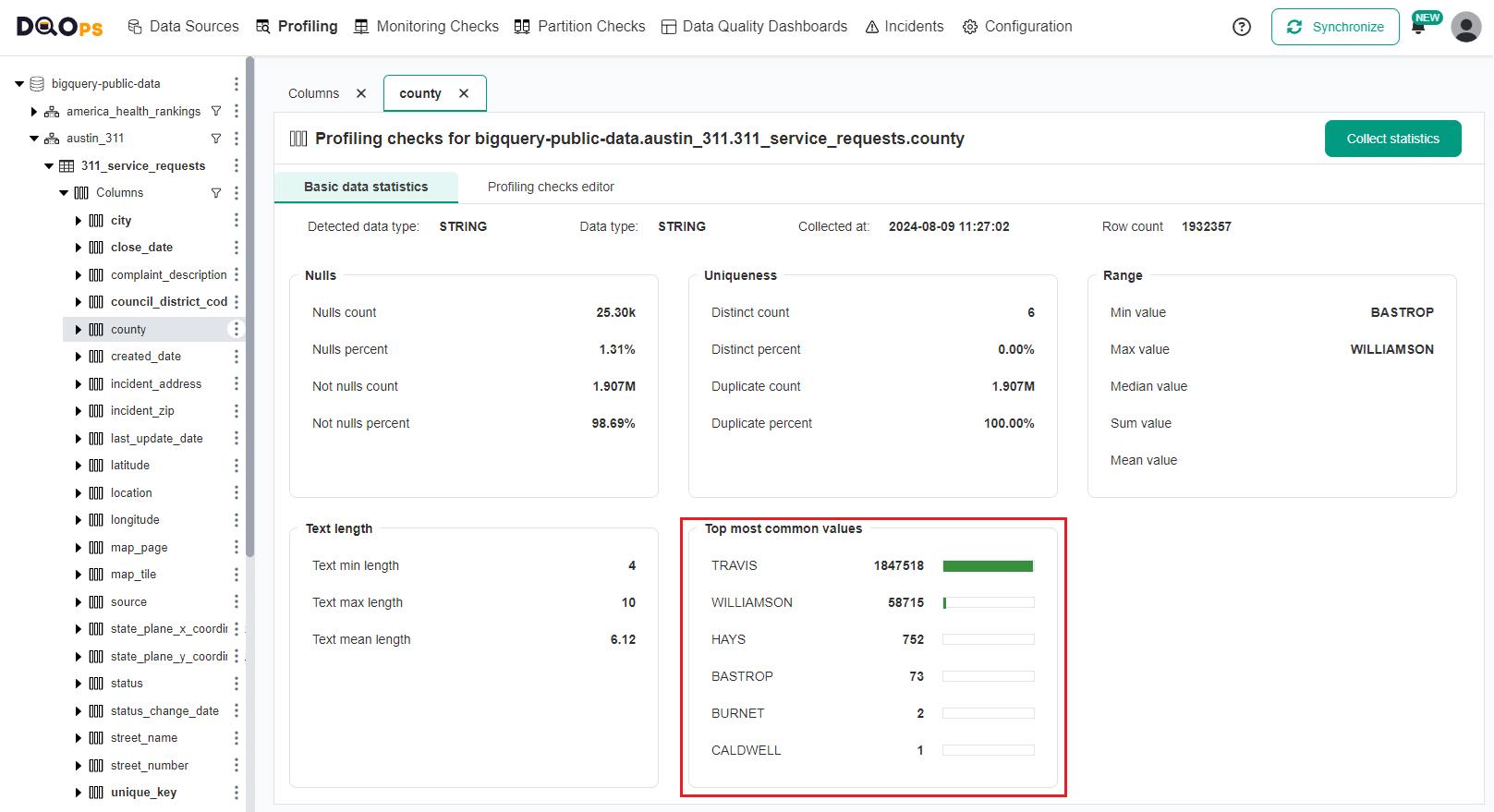
The examples of testing accepted values will use a 311 Austin municipal services call history table. The table contains requests from six counties in the Austin metro area: Travis, Williamson, Hays, Bastrop, Burnet and Caldwell. The column profiling results confirm that all service calls reported in the table are in these counties, written in capital case.
Verify that ONLY accepted values are used
The most common data quality issue affecting columns that store well-known values is the presence of values outside the list of expected values. We know all the possible values that should be stored in a column, and want to ensure that no unknown value is accidentally stored there. Invalid values may appear due to typing mistakes or errors in the data transformation code.
DQOps has a dedicated data quality check for testing if a column contains only valid (expected) values. This data quality check has two variants for text and numeric data types.
-
text_found_in_set_percent for testing text columns
-
number_found_in_set_percent for testing numeric columns
Configure the check in UI
The text_found_in_set_percent check measures the percentage of rows that contain only one of the expected values in the column. The min_percent parameter controls the minimum accepted percentage of rows. To verify that all rows contain only the expected values, set the parameter to 100%.
This data quality check requires a list of expected values that will be used to test the values in the column. These expected values should be specified in the expected_values parameter, which should be a list (array) of values.

The list of the expected values is configured in a popup window.
Configure the check in YAML
DQOps stores the configuration of both the text_found_in_set_percent and number_found_in_set_percent checks in a YAML file. The following sample YAML file shows the configuration of a daily monitoring check that tests accepted values daily.
Text found in set percent error sampling in UI
To assist with identifying the root cause of errors and cleaning up the data, DQOps offers error sampling for this check. Let’s remove the CALDWELL value from the expected_values and run the check again. Now the check failed and you can view representative examples of data that do not meet the specified data quality criteria by clicking on the Error sampling tab in the results section.
For additional information about error sampling, please refer to the Data Quality Error Sampling documentation.
Defining data dictionaries
Xem thêm : Filters
DQOps supports defining reusable data dictionaries. The data dictionaries are simple CSV files without the header line. Please read the concept of referencing data dictionaries guide to learn more.
The screens for defining data dictionaries are found in the configuration section of the DQOps user interface. The following example shows how to add a data dictionary named austin_counties.csv.
The data dictionary list screen shows a dictionary reference token used in the data quality checks to reference the data dictionary. The token to access the austin_counties.csv dictionary is ${dictionary://austin_counties.csv}.
Referencing dictionaries in UI
The dictionary reference is used as one of the values for the expected_values parameter. DQOps supports referencing multiple data dictionaries, which are merged. Mixing standalone values and data dictionaries is also supported.
Referencing dictionaries in YAML
When used in a YAML file, the data dictionary reference token should be wrapped in double quotes.
Verify that ALL accepted values are in use
DQOps has data quality checks to ensure all the expected values are used in the column. This type of check is useful for testing that the most common values are always used, especially that the expected values are present in every partition. The list of expected values can be a subset of all possible values.
DQOps has two types of checks for testing that all accepted values are in use.
-
expected_text_values_in_use_count tests text columns, the list of expected values contains texts.
-
expected_numbers_in_use_count tests numeric columns, the list of expected values contains numbers.
Despite the suffix _count at the name of these checks, they are counting expected values that were not found in the column. It differs from the concept of other _count data quality checks in DQOps that count rows.
Configure the check in UI
The configuration of the expected_text_values_in_use_count check is very similar. Please note that the DQOps data quality check editor shows this check after clicking the Show advanced checks checkbox.
The max_missing rule parameter configures the maximum number of expected values that can be missing in the column. Use the value 0 for the max_missing to test that all the expected values are in use.
Configure the check in YAML
The configuration of the expected_text_values_in_use_count check in YAML is straightforward.
Data quality issue example
The following example shows the difference between the text_found_in_set_percent and expected_text_values_in_use_count checks when an unreferenced value is configured in the expected values list. The COMAL value is a nearby county name. The table does not have any rows containing that value.
The text_found_in_set_percent check passes because the first SIX county names are found in the column, even if COMAL is absent. The expected_text_values_in_use_count check fails because no row contains the expected COMAL value.
Testing the most common values
Xem thêm : Eyelid Q&A: How I Went from Monolids to Double Lids
The result of the column profiling displays the frequency of each column value, arranged from the most common to the least common values. The top two counties, TRAVIS and WILLIAMSON, are the most frequently occurring values.
We can use the expected_texts_in_top_values_count data quality check to ensure that these two county names are always the most common values in the column.
Configure the check in UI
The expected_texts_in_top_values_count data quality check has two parameters.
-
The expected_values parameter is a list of values that should be most common in the column.
-
The top parameter allows us to expand the range of top values.
The value for the top parameter should be at least equal to the number of expected values. In that case, DQOps verifies that all the expected values are still the most common ones in the column. The top value can be higher. We can test that two expected values are always in the column’s top three most common texts.
The max_missing rule parameter controls the tolerance for missing expected common values. When the max_missing rule parameter is 0, DQOps must find all expected values at the top. The parameter value 1 allows one missing value, and so on.
Configure the check in YAML
The configuration of the expected_texts_in_top_values_count check in YAML is straightforward.
Validating country codes
DQOps also has built-in data quality checks for validating two-letter country codes and currency names. These checks were tested to work on all supported data sources.
If you need to create a custom data quality check that is easy to activate, the best way is by making a copy of the text_valid_country_code_percent check and adapting the list of accepted values used in the query template (the data quality sensor).
Activating country code validation in UI
The text_valid_country_code_percent check takes one parameter min_percent. This parameter sets the minimum percentage of values that must be valid country codes.
The following example shows that a public dataset showing the daily count of COVID-19 cases per country uses some invalid country codes.
Activating country code validation in YAML
The text_valid_country_code_percent check is easy to configure. It does not require a list of accepted values because the list is already included in the SQL query template.
Use cases
Name of the example Description Percentage of rows having only accepted values This example shows how to verify that a text column contains only accepted values using the text_found_in_set_percent check. Percentage of valid currency codes This example shows how to measure that the percentage of valid currency codes in a column does not fall below a set threshold using text_valid_currency_code_percent check.
List of accepted values checks at a column level
Data quality check name Friendly name Data quality dimension Description Standard check text_found_in_set_percent Minimum percentage of rows having text values outside the list of expected values Validity A column-level check that calculates the percentage of rows for which the tested text column contains a value from a set of expected values. Columns with null values are also counted as a passing value (the sensor assumes that a ‘null’ is also an expected and accepted value). The check raises a data quality issue when the percentage of rows with a not null column value that is not expected (not one of the values in the expected_values set) is below the expected threshold. For example, 99% of rows should have values from the defined domain. This data quality check is useful for checking text columns that have a small number of unique values, and all the values should come from a set of expected values. For example, testing country, state, currency, gender, type, and department columns whose expected values are known. number_found_in_set_percent Minimum percentage of rows having numeric values outside the list of expected values Validity A column-level check that calculates the percentage of rows for which the tested numeric column contains a value from a set of expected values. Columns with null values are also counted as a passing value (the sensor assumes that a ‘null’ is also an expected and accepted value). The check raises a data quality issue when the percentage of rows with a not null column value that is not expected (not one of the values in the expected_values set) is below the expected threshold. For example, 99% of rows should have values from the defined domain. This data quality check is useful for checking numeric columns that store numeric codes (such as status codes) to see if the only values found in the column are from the set of expected values. expected_text_values_in_use_count Maximum number of expected text values that are not in use Reasonableness A column-level check that counts unique values in a text column and counts how many values out of a list of expected string values were found in the column. The check raises a data quality issue when the threshold for the maximum number of missing has been exceeded (too many expected values were not found in the column). This check is useful for analysing columns with a low number of unique values, such as status codes, to detect whether all status codes are used in any row. expected_texts_in_top_values_count Verify that the most popular text values match the list of expected values Reasonableness A column-level check that counts how many expected text values are among the TOP most popular values in the column. The check will first count the number of occurrences of each column’s value and will pick the TOP X most popular values (configurable by the ‘top’ parameter). Then, it will compare the list of most popular values to the given list of expected values that should be most popular. This check will verify how many supposed most popular values (provided in the ‘expected_values’ list) were not found in the top X most popular values in the column. This check is helpful in analyzing string columns with frequently occurring values, such as country codes for countries with the most customers. expected_numbers_in_use_count Maximum number of expected numeric values that are not in use Reasonableness A column-level check that counts unique values in a numeric column and counts how many values out of a list of expected numeric values were found in the column. The check raises a data quality issue when the threshold for the maximum number of missing has been exceeded (too many expected values were not found in the column). This check is useful for analysing columns with a low number of unique values, such as status codes, to detect whether all status codes are used in any row. text_valid_country_code_percent Minimum percentage of rows containing valid country codes Validity This check measures the percentage of text values that are valid two-letter country codes. It raises a data quality issue when the percentage of valid country codes (excluding null values) falls below a minimum accepted rate. text_valid_currency_code_percent Minimum percentage of rows containing valid currency codes Validity This check measures the percentage of text values that are valid currency names. It raises a data quality issue when the percentage of valid currency names (excluding null values) falls below a minimum accepted rate.
Reference and samples
The full list of all data quality checks in this category is located in the column/accepted_values reference. The reference section provides YAML code samples that are ready to copy-paste to the .dqotable.yaml files, the parameters reference, and samples of data source specific SQL queries generated by data quality sensors that are used by those checks.
What’s next
- Learn how to run data quality checks filtering by a check category name
- Learn how to configure data quality checks and apply alerting rules
- Read the definition of data quality dimensions used by DQOps
Nguồn: https://buycookiesonline.eu
Danh mục: Info
This post was last modified on November 25, 2024 5:21 am